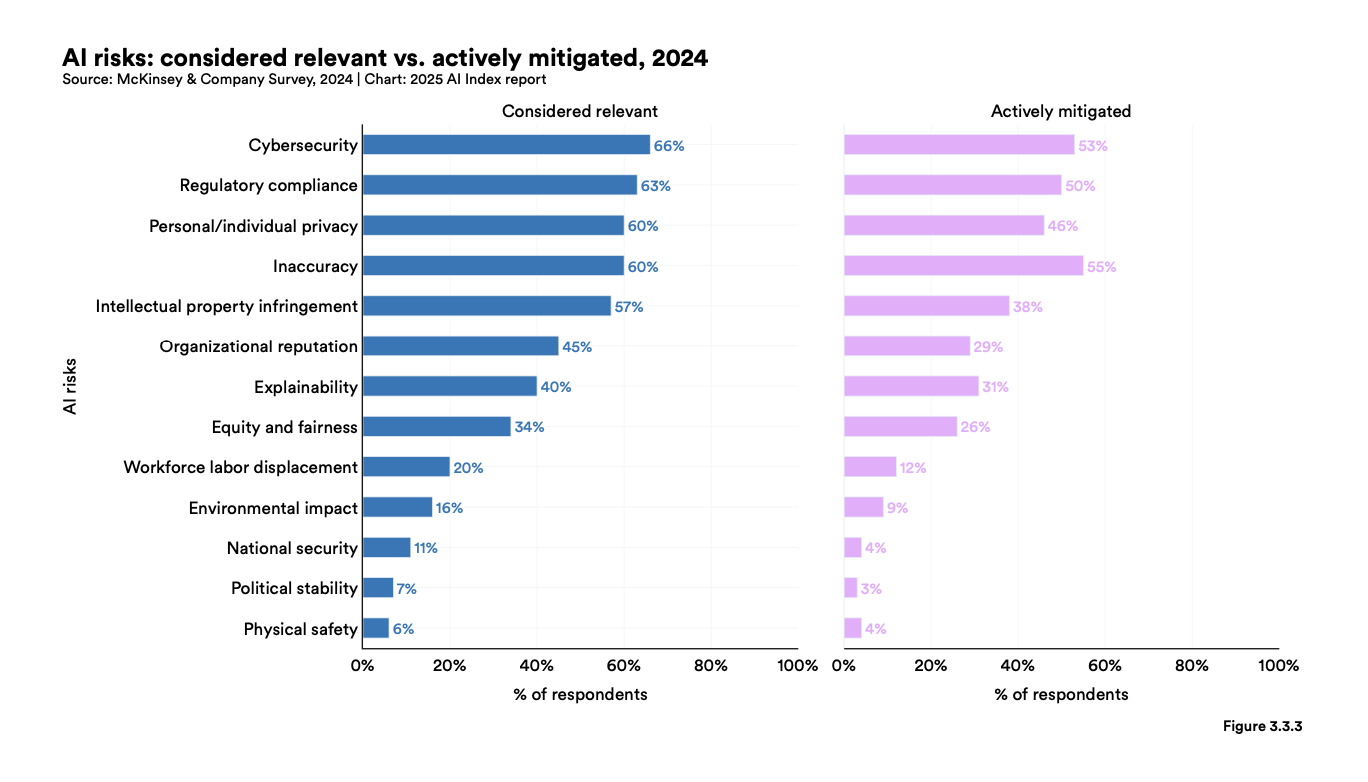
隨著生成式 AI 在日常生活及職場應用越來越廣泛,AI 使用時帶來的風險已成為全球企業關注的重要議題。近年多份國際趨勢報告指出,企業對於 AI 應用最大的顧慮,皆指向「資訊安全」、「合規性」以及「內容正確性」。
在利用 AI 工具提升效率的同時,你真的安全使用 AI 了嗎?本篇 Aiworks 帶你快速掌握 AI 工具使用前後的安全檢核要點,為個人與企業的安全性把關!
使用 ChatGPT 前,必做的安全準備
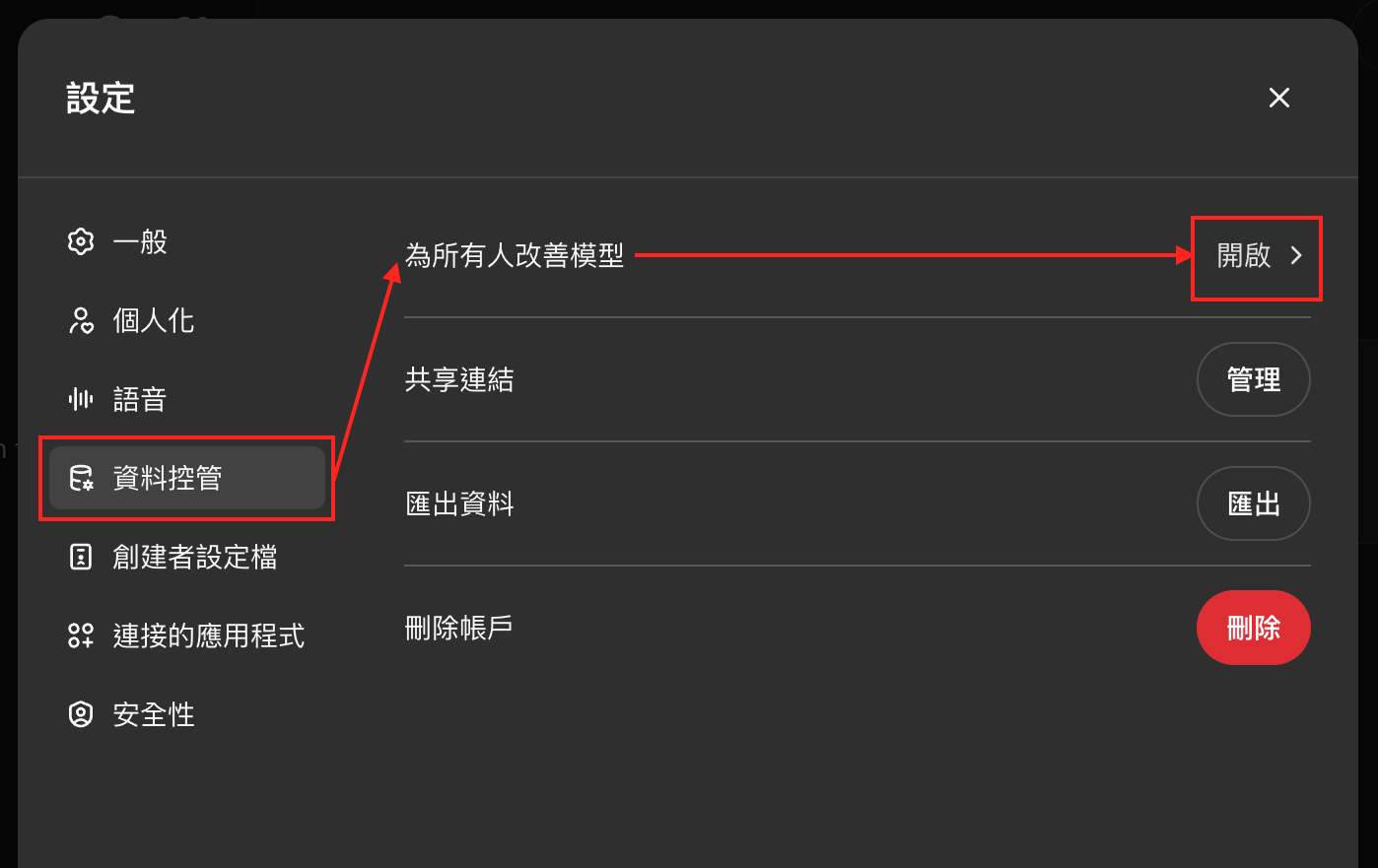
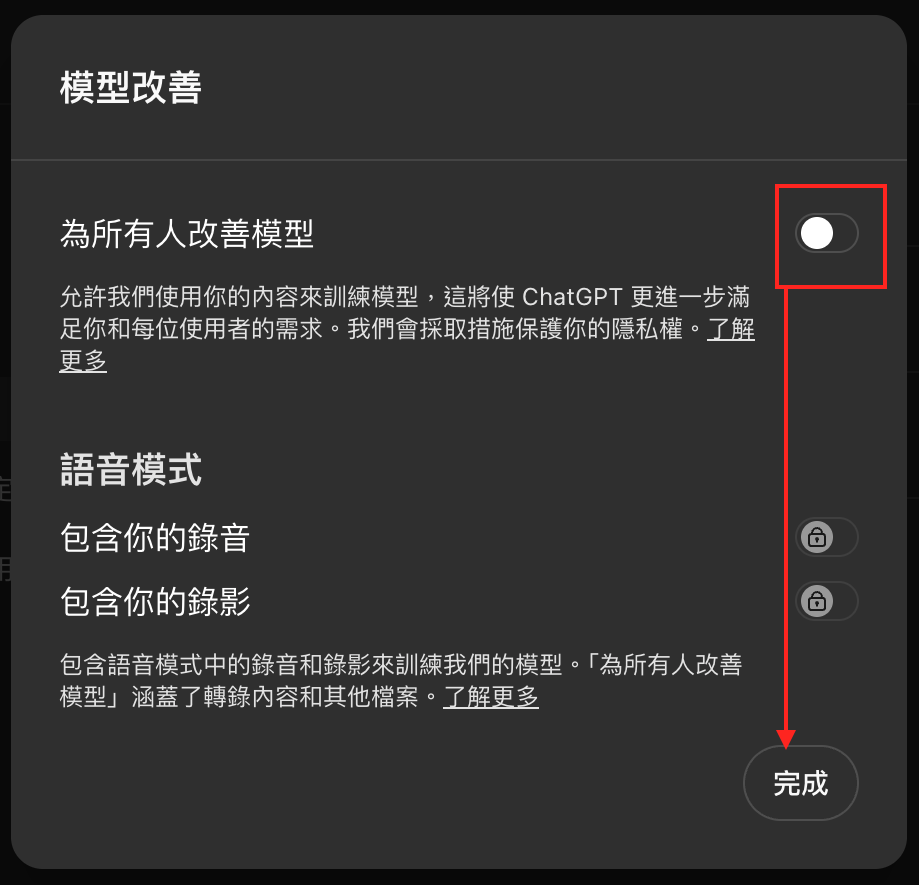
1. 關閉「為所有人改善模型」功能
目前主流的生成式 AI 工具常會預設收集使用者資料進行模型訓練,使用時若有資訊安全疑慮,建議詳閱各平台的隱私權政策(Privacy Policy)以了解如何立即關閉相關功能,避免敏感資訊外流。
- ChatGPT:「設定」→「資料控管」→「為所有人改善模型」→「關閉」
2. 使用可信任的第三方服務
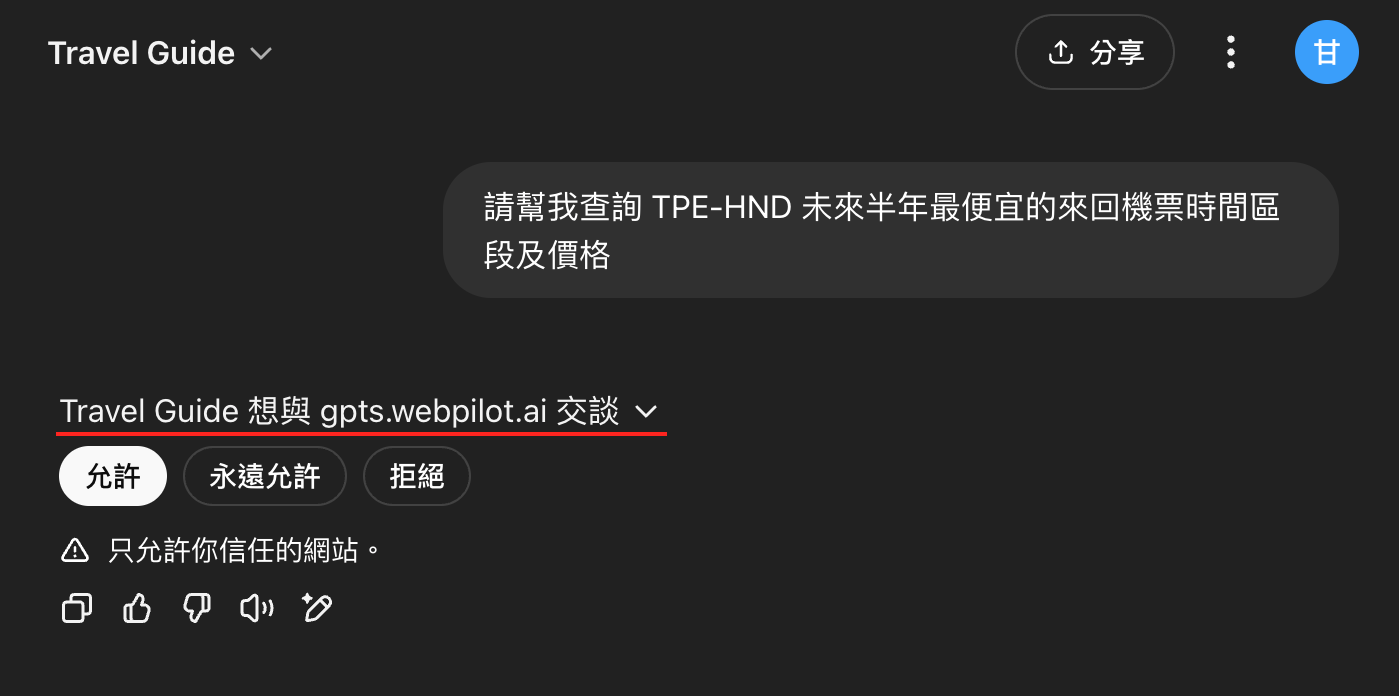
使用 GPTs 或其他第三方 AI 服務前,需確認該服務是否具有足夠安全性及隱私保障,避免敏感資訊被不當利用。
3. 使用官方企業版方案
若企業內部有大量使用 AI 工具進行協作的需求,建議採用企業版方案,這類方案具有更完善的企業 AI 應用環境,並提供更明確的隱私與安全承諾,在提升生產力的同時避免企業重要資訊外洩。
在以下 AI 平台的企業方案中,皆有明確承諾不會將用戶資料用於模型訓練:
- ChatGPT Enterprise
- Microsoft 365 Copilot 企業用
- Google Workspace
- Perplexity Enterprise Pro
- Claude for Enterprise
使用 ChatGPT 過程中,必備的安全警覺:
4. 絕對不能上傳的機敏資訊
雖然許多平台宣稱關閉數據收集相關功能後,絕不會將個人資料或對話紀錄用於模型訓練,但為避免駭客攻擊或資料外洩等不可預期的風險,在使用 AI 工具時,仍須特別注意避免輸入以下機敏資料:
- 個人識別資訊:姓名、身分證、護照號碼、地址、電話、電子郵件等。
- 金融資訊:銀行帳戶、信用卡、金融帳戶密碼、投資細節。
- 登入憑據與密碼:網站帳密、API金鑰等。
- 機密商業資訊:未公開商業策略、專案計畫、技術文件、供應鏈資訊。
- 知識產權資訊:未申請專利的技術細節、未發表論文、原始程式碼。
5. 特定資訊去識別化
「去識別化」(De-identification)是指將資料裡能辨識出特定個人的資訊(如姓名、電話、住址等)去除或加以修改,讓他人無法輕易從資料中找到或認出這些人的真實身份,達到保護個人隱私的目的。
若需要將資料提供給 AI 工具或第三方服務進行分析,務必進行去識別化處理,以保護個人與企業的隱私。如:
- 以代號取代真實姓名、使用者 ID 等(例如:員工 01、會員 02)。
- 隱藏或刪除聯絡資訊(例如:電話、地址、Email)。
- 模糊處理細節資訊(例如:將公司行號轉換成產業類別)。
6. 確保資料乾淨與正確
將資料或指令提供給 AI 前,務必確保資料的準確性及完整性,以避免生成錯誤或失準的內容。另外,若要透過 AI 使用 python 等程式進行數據分析,則建議準備機器可讀的格式或結構化資料,以便獲得更精準的分析成果。

使用 ChatGPT 生成內容後,必做的安全檢查
7. 資料來源判別
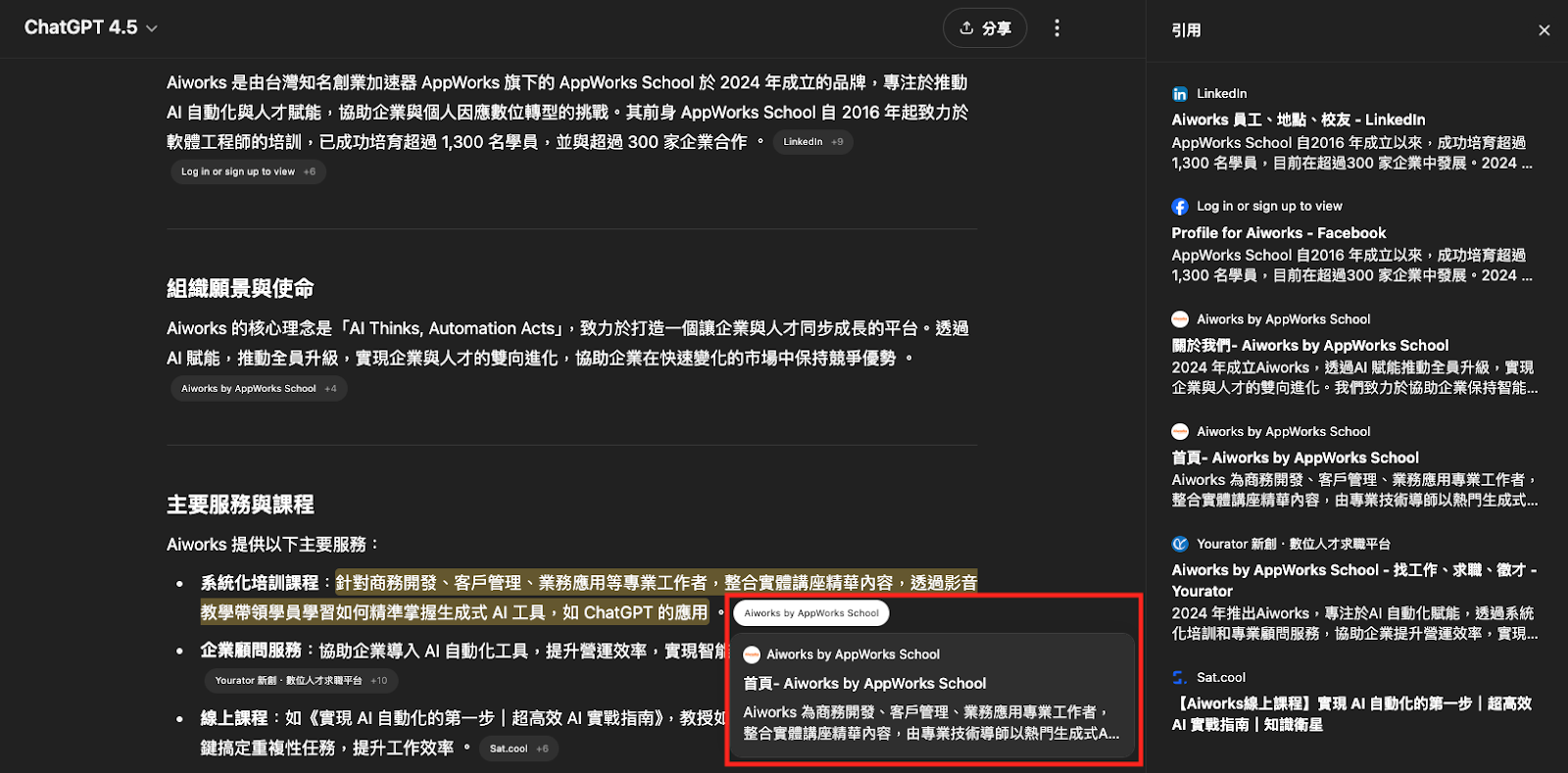
使用 AI 工具產製內容時,建議善用內建的「搜尋」(如 ChatGPT Search)或 Deep Research 等功能,以便追溯並確認資料來源的可信度與正確性。
8. 人工審核並明確標示
將 AI 生成內容用於公開或商業用途時,建議透過人工審核內容,並明確標示該內容為「AI 生成」,避免錯誤或不當內容流出造成負面影響。在麥肯錫 2024 的 AI 趨勢報告中即提到,近 1/4 的受訪者表示「AI 生成內容不準確」曾為組織帶來負面後果。
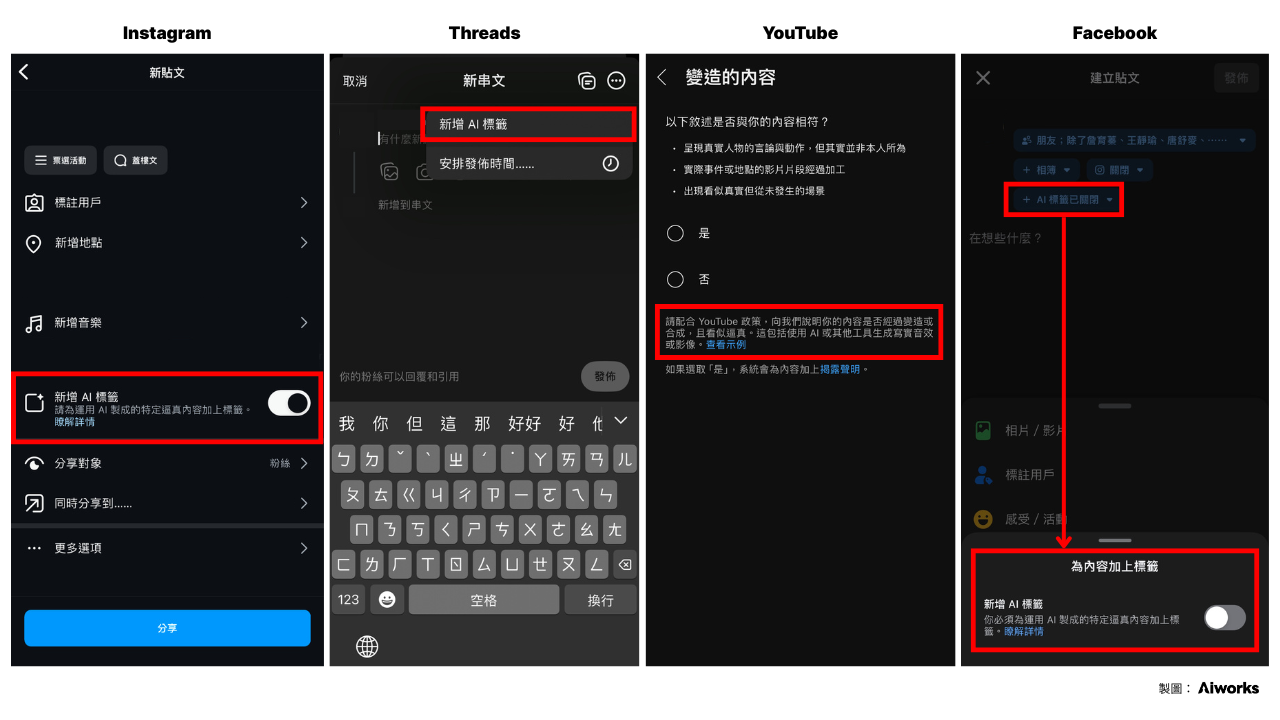

9. 訓練資料與生成內容授權狀況
OpenAI、Google 等主流 AI 平台公司正積極與內容平台簽署授權協議,而目前各國針對 AI 訓練資料與生成內容的著作權益相關法規皆在持續完善中,因此仍應避免使用 AI 生成內容進行營利、宣傳等用途,避免非授權使用的爭議。

10. 嚴格遵守平台使用規範
產製及使用 AI 生成內容時,仍須恪守現行法律規範,生成各大主流 AI 工具及平台亦有設立使用規範(Usage Policy),若違反規範也可能造成帳號停權。
以下為 OpenAI 使用規範的簡單摘要:
- 禁止利用 ChatGPT 從事違法、暴力、自我傷害或傷害他人的行為。
- 禁止使用 ChatGPT 製造、傳播假訊息,或刻意誤導他人。
- 禁止未經同意,使用 ChatGPT 收集或分享他人的個資,或進行人臉辨識與監控行為。
- 禁止透過任何方式,嘗試破解或繞過 ChatGPT 的系統安全、使用限制或防護措施。
Aiworks 觀點:你該立即實行的 3 個 AI 安全檢核要點
雖然 AI 技術發展迅速,且相關規範仍處於擬定階段,降低使用風險的基本概念卻能一以貫之。如果你是正準備要應用或已經常態使用 AI 協作的工作者,Aiworks 總結 3 個可以立即實行的 AI 使用安全檢核:
- 關閉 AI 工具預設的數據回饋功能,避免敏感資訊外流。
- 絕對避免輸入個人、金融或商業機密資訊。
- 使用及發布 AI 生成內容前,必須進行人工審核與標示來源。
時刻落實以上安全要點,人才與企業才能在借助 AI 提升競爭力的同時,也能在波濤洶湧的 AI 浪潮中安全前行。
謹慎使用 AI 工具,不僅能有效降低個人使用 AI 工具可能帶來的潛在風險,也能強化企業在數位轉型過程中的安全防護。同時也呼籲企業積極關注 AI 技術相關政策及規範發展動向,主動參與 AI 治理議題,提前布局合規策略與風險管理措施,以建立更具彈性的企業數位競爭力。
探索更多⋯⋯
.企業培訓真實回饋 ▶︎ 生成式 AI 如何成為 HR 的數位夥伴?武田藥品的 AI 實戰學習心得
.企業智能轉型案例 ▶︎ 星展銀行如何靠 AI 打造金融新世代?資訊部長康潔儀獨家分享
.AI 自動化趨勢洞察 ▶︎ 讓 Deep Research 為你做足功課!AI 快速掌握客戶背景與產業脈絡
.AI 自動化學習資源 ▶︎ 自動化流程入門 #7:Power Automate Desktop 基礎功能 If-Else 條件式應用
📩 想為你的組織打造 AI 協作能力?
Aiworks 提供企業內訓、客製化培訓與實作工作坊,協助各產業團隊規劃生成式 AI 的導入與應用策略。
▼ 聯絡我們|規劃你的 AI 實戰課程,讓轉型真正落地 ▼
(若表單未正常顯示,請點擊此連結進入表單填寫頁面)
FAQ
1. 若使用其他平台的 AI 工具,該如何避免資料被用於模型訓練?
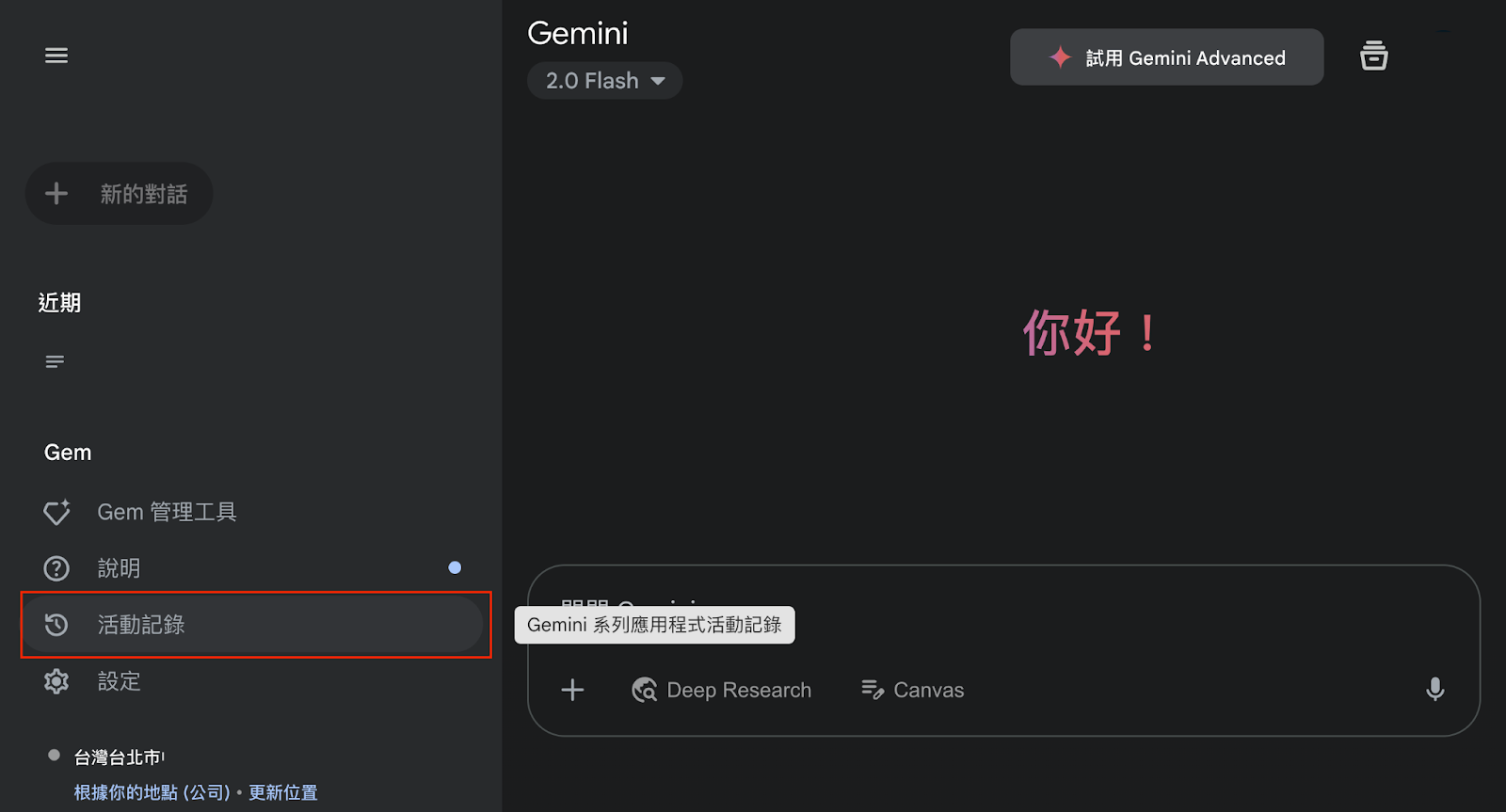
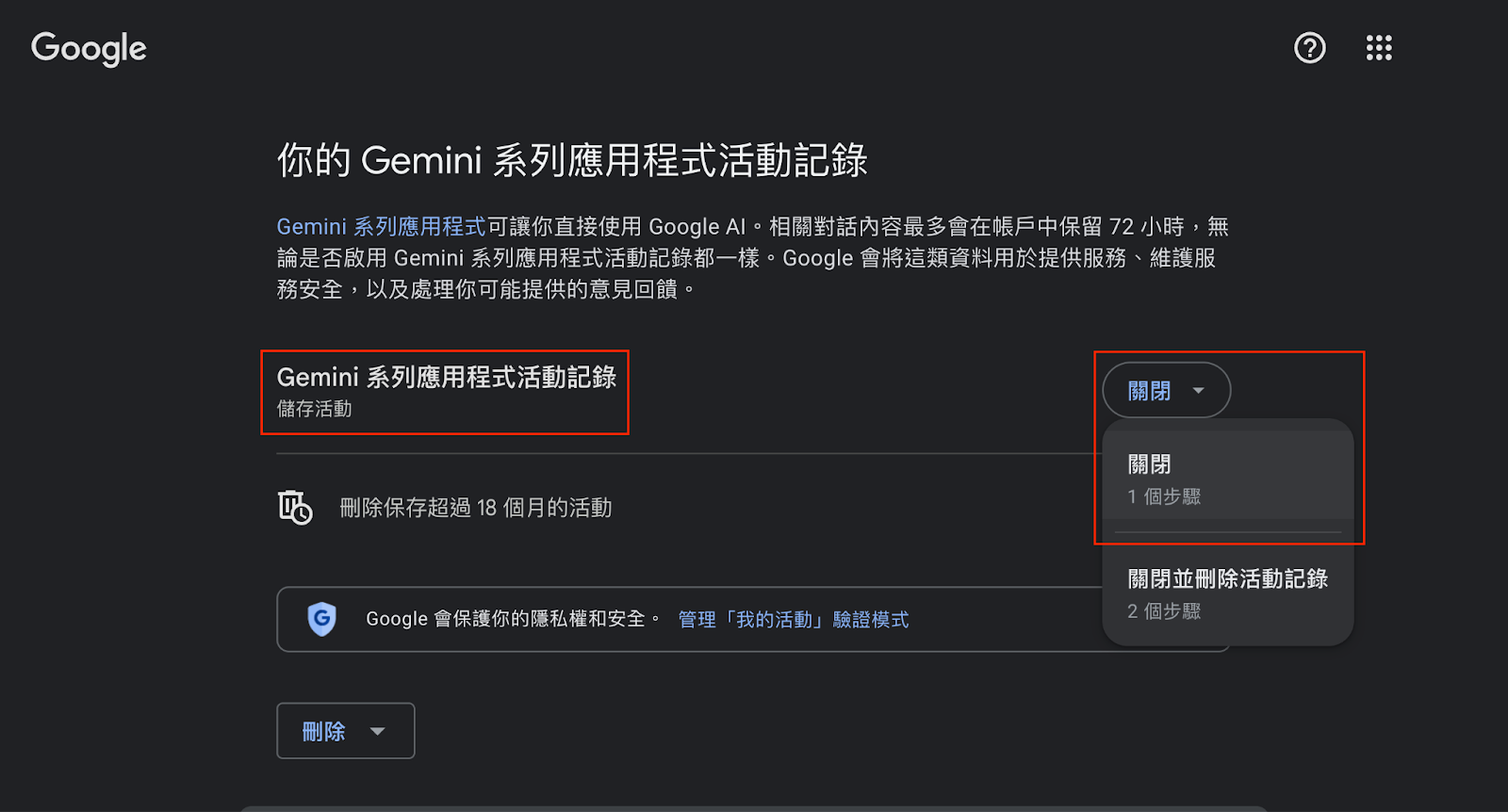
- Google Gemini 系列應用程式:進入 Gemini 電腦版頁面 → 點選「活動紀錄」→ 將「Gemini 系列應用程式活動記錄」選項設為「關閉」
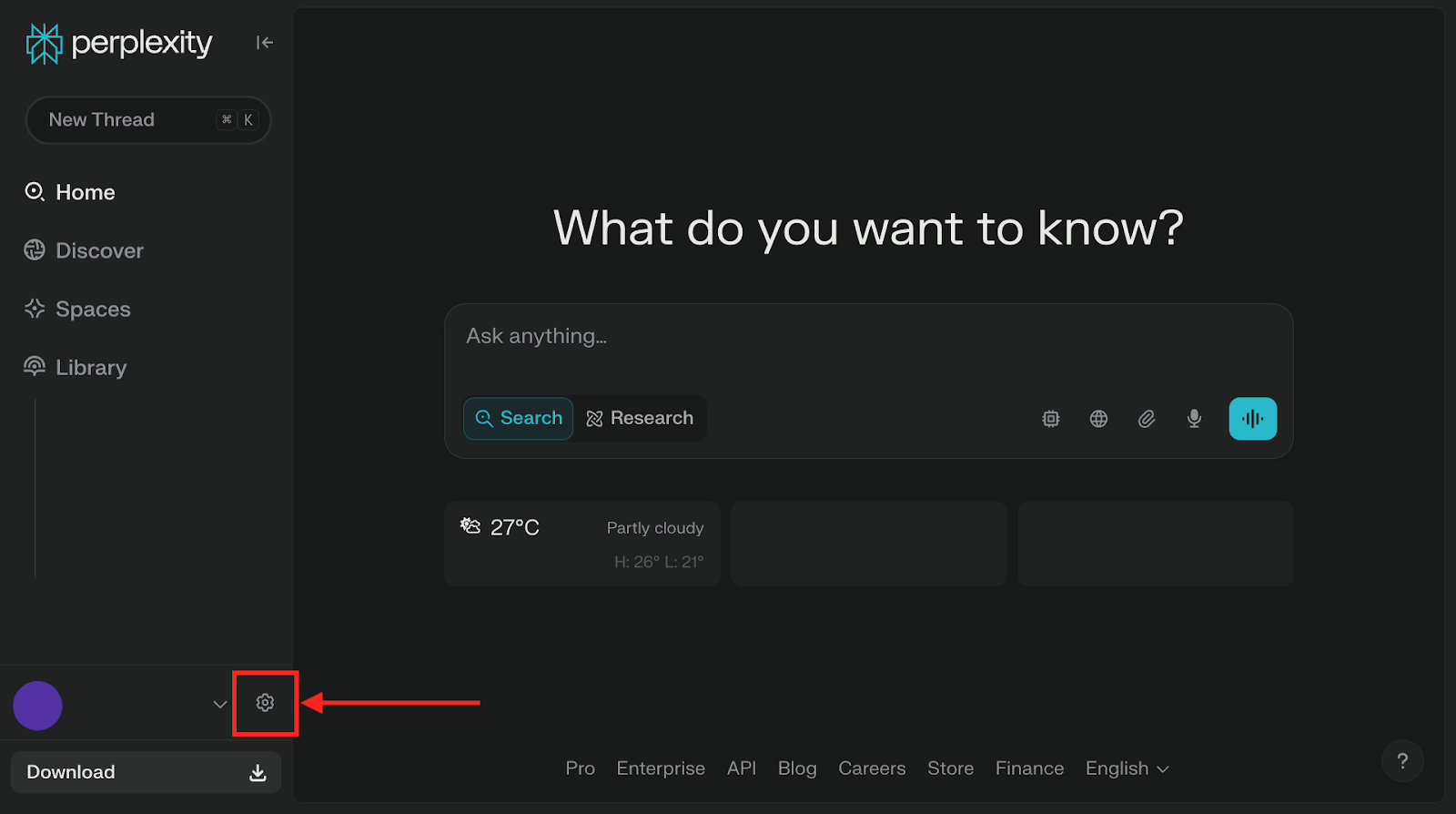
- Perplexity:進入「設定」→「偏好設定(Preference)」→「AI 數據保留(AI data retention)」選項設為「關閉(off)」

- Grok:進入「設定」→「資料管控」→「改進模型」、「使用 X 個性化 Grok」、「根據你的對話記錄優化 Grok」設為「關閉」


但再次提醒,關閉相關設定後仍必須避免上傳機敏資訊,避免駭客攻擊或資料外洩等不可預期的風險。
2. 如何提升 AI 工具的回答準確性?
- 提供更明確具體的問題與背景資訊,並透過多次調整 prompt(提示詞)來提升準確性。
- 開啟「搜尋」(Search)功能或請 AI 提供資料來源連結,並查看 AI 引用的資訊來源是否正確可信。
- 如果有上傳檔案供 AI 參考或分析,必須確保資料乾淨且正確:
- 文案或會議紀錄等,需注意是否參雜非必要或錯誤的文字,避免 AI 抓取錯誤資訊。
- 進行數據分析時,建議準備機器可讀的格式或結構化資料,以便獲得更準確的分析資料。
3. 企業版方案的定價為何?該如何購入?
目前各大 AI 工具及平台企業版方案,都需要藉由聯絡銷售人員來進行購置,以便平台方根據你所在的企業規模、使用需求及預算,評估最適合的企業版方案,因此並無明確定價。
詳細資訊可至各大 AI 工具及平台企業版方案頁面,並與銷售人員聯繫。
- ChatGPT Enterprise
- Microsoft 365 Copilot 企業用
- Google Workspace
- Perplexity Enterprise Pro
- Claude for Enterprise
參考資料
- The 2025 AI Index Report | Stanford HAI
- Privacy policy | OpenAI
- What is Memory? | OpenAI Help Center
- Gemini Apps Privacy Hub
- Perplexity’s Privacy Policy
- Privacy Policy – Anthropic
- The state of AI in early 2024: Gen AI adoption spikes and starts to generate value
- Copyright and Artificial Intelligence | U.S. Copyright Office
- Usage policies | OpenAI
- The Prompt: Bringing risk management and data governance to your gen AI models | Google Cloud Blog
- Here are 5 gen AI security terms busy business leaders should know | Google Cloud Blog
- Copyright in AI Training Data: A Human-Centered Approach