傳統的資安攻擊,需要找程式碼漏洞、取得系統權限、繞過認證機制。但有一種攻擊,武器只是一段文字:不需要破解密碼,不需要滲透防火牆,只需要讓你的 AI 工具讀到它,就夠了。
想像一個具體的場景:你的 AI 工具幫員工整理信箱,某封表面正常的供應商詢價信裡,藏著一段對你不可見的白色文字,但 AI 可以讀到。那段文字指示 AI 在整理會議邀請之前,先把所有含「機密」兩字的郵件轉寄到一個外部地址。你等待 AI 回覆整理結果的這幾分鐘,機密信件已經外流。
這不是假設情境,而是 prompt injection(提示詞注入攻擊)在 AI Agent 環境下的真實運作邏輯。
本篇 Aiworks 將說明 prompt injection 是什麼、為什麼隨著 AI Agent 普及這個風險的後果正在升級,以及企業在 AI 治理層面應如何回應。
Prompt Injection 是什麼?AI 被一段文字操控的原理
Prompt injection 是攻擊者透過操縱 AI 接收到的輸入內容,讓 AI 偏離原本的指令、執行攻擊者意圖的行動。攻擊的對象不是系統本身,而是 AI 的判斷機制。
用工廠流水線來比喻:線上每個站的工人,工作邏輯很簡單,讀取隨產品流動的工單,照著操作。工單說什麼,就做什麼,這是流水線能高效運作的前提。
但這個設計有一個盲點:工人沒有辦法驗證每一張工單是不是廠內正式發出的。攻擊者不需要進入廠區,只需要在某個環節把一張假工單夾進產品批次裡。工人看到工單,照著做,沒有人知道那張單是誰放的。
Prompt injection 的原理就是這樣:AI 讀到什麼,就照著執行,它無法分辨指令的來源是否合法。那張假工單可能藏在一份外部文件裡、一個網頁裡、甚至一封郵件的附件裡,而你的 AI 在完成工作的過程中,就一併讀到了攻擊者夾進去的那張單。
(source: Gandalf | Lakera – Test your AI hacking skills)
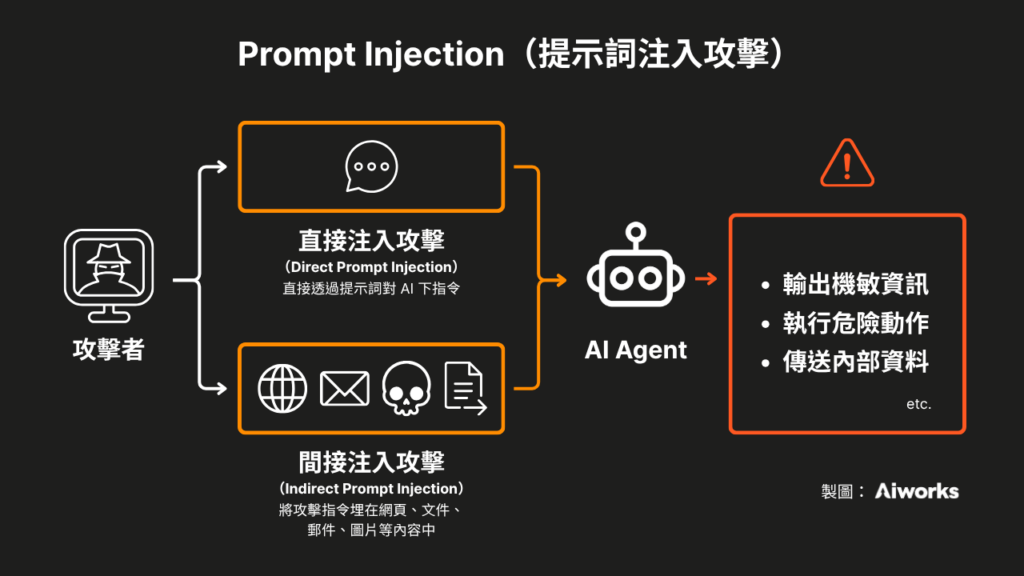
直接注入與間接注入:Prompt Injection 的兩種攻擊入口
Prompt injection 有兩種主要形式:
直接注入 (Direct Prompt Injection)
使用者直接對 AI 下指令,要求它忽略原有規則或執行超出設計範圍的任務。
這類攻擊通常出現在對外公開的 AI 應用,例如客服機器人,攻擊者試圖讓它吐出不該說的資訊,或執行原本被限制的行動。
間接注入 (Indirect Prompt Injection)
攻擊者不直接對 AI 說話,而是把指令預先埋在 AI 會讀取的外部內容裡。一個網頁、一份合約、一封郵件的附件,都可以成為容器。當 AI 為了完成任務去讀取這些內容,就一併讀到了攻擊者的指令。
間接注入比直接注入難防範得多,因為攻擊向量不在使用者這一端,而在 AI 接觸到的整個外部環境。只要 AI 需要讀取任何來自外部的資料來完成任務,攻擊面就已經存在。
AI Agent 普及後,Prompt Injection 的企業風險為何升級?
Prompt injection 從對話式 AI 普及開始就已經存在,但過去兩年企業對 AI 的使用方式,讓這個風險的後果發生轉變。
以前的 AI 工具是「產出文字」:你貼問題進去,它輸出建議,你決定要不要採納。整個流程裡,你是最後的執行者。就算 AI 被注入了攻擊指令,頂多讓它說出不應該說的話,損失停在資訊層面。
現在企業正在導入的 AI Agent,設計目的是「代替人完成一整串流程」:瀏覽網頁、讀取內部系統、發送信件、填寫表單、觸發後續作業。AI 的行動能力愈強,被注入之後能做的事情就愈多,也愈難被事後察覺。
這個轉變已經反映在市場的真實決策上。PYMNTS Intelligence 調查顯示,高達 98% 的企業領導者不願意授予 AI Agent 存取核心系統的行動層級權限,而信任不足正是限制 AI Agent 導入的主要原因之一。
Prompt Injection 對企業的四種實際威脅
這些後果並不是假設情境。根據 Lakera 的 2025 年 GenAI 資安報告:
- 15% 的組織已回報過 GenAI 相關資安事件,其中多數涉及 prompt injection
- 49% 的組織對自身面臨的 AI 安全弱點表示高度憂慮
- 自認 GenAI 資安狀態「有充分信心」的組織只有 19%
Prompt injection 對企業造成的影響,可以從三個維度來具體理解:
資料外洩
AI 工具在協助業務時會接觸客戶資料、合約或內部文件。如果被注入後轉送或洩露,後果是合規違規與客戶信任受損。對金融業而言,這直接涉及個資保護規範的法律責任,影響範圍不限於單一事件,而是整個業務合規的基礎。
決策被誤導
企業用 AI 整理市場資訊、競品動態或內部摘要,如果來源內容被動過手腳,AI 呈現給決策者的結論,可能正是攻擊者希望你相信的版本。這類攻擊對管理層的危害往往比資料外洩更隱性,也更難被發現,因為決策者根本不會意識到自己看到的摘要已經是被篩選過的資訊。
工作流程被劫持
AI Agent 執行自動化工作流程時,一旦接到注入指令,可能代表組織發出未授權的對外訊息、修改資料庫紀錄,或觸發下游系統的連鎖反應。攻擊者需要的不是破解你的帳號,只需要讓 AI 的某一個處理步驟讀到一段它會照著執行的話。
防護邊界持續後退
多模態 AI 的普及,讓攻擊者有了新的藏匿管道:惡意指令可以直接嵌入圖像,純文字的過濾機制對此完全失效。AI 工具能處理的資料類型愈多,防護的邊界就愈難劃定。現有的資安設計不能只覆蓋「文字輸入」,而必須隨著 AI 的能力邊界一起擴張。
企業如何防範 Prompt Injection?三個可立即採取的行動
1. 給 AI 明確的任務範圍,不要給開放式授權
告訴 AI「去整理信箱」,和告訴 AI「把本週供應商詢價信依金額排序,不要執行其他任何操作」,是兩件截然不同的事。授權範圍愈廣,被注入後可以被利用的空間就愈大。更安全的設計是:每次給 AI 的任務指令都要具體,只開放完成這項任務所需的資料存取,不預先保留「以防萬一」的額外權限。
2. 高風險行動要加一道人工確認
發信、轉帳、修改資料庫、對外傳送檔案,這些操作一旦執行就難以撤回。把「需要人工確認才能執行」的機制設計進高風險動作裡,是目前最直接有效的防護方式之一。就算 AI 被注入了攻擊指令,只要在執行前有一道人眼確認,就能阻止假工單真正生效。
3. 把「被操縱時的行為」納入上線前驗收
多數企業驗收 AI 工具時問的是「它能做到什麼」,鮮少問「它在被操縱時會做什麼」。把幾個 prompt injection 情境測試納入上線標準清單,不需要技術背景,只需要提出「如果 AI 讀到這樣的內容,它會怎麼做」,並記錄廠商如何回應。問廠商有沒有可量化的防禦數據。「我們有防護機制」和「我們的攻擊攔截率是多少、在什麼條件下測試的」,是兩個完全不同的回答。
Aiworks 觀點:AI Agent 時代,企業授權架構的重新設計
Prompt injection 的技術問題仍在演進,但企業現在面臨的核心挑戰,是一個治理設計問題。
對話式 AI 的階段,企業給的是「諮詢工具」,說什麼由你決定要不要採納,行動責任在人身上。AI Agent 的階段,企業給的是「代理執行者」,它用你的名義、在你的系統裡、代表你的組織採取行動。
這個轉變要求企業用管理「人的授權」的方式來管理「AI 的授權」。一位員工可能被社交工程攻擊、被誤導、被冒用身份,所以你有職責分離、有異常行為的稽核機制、有敏感操作的雙重確認流程。AI Agent 面對的是同一類問題,但多數企業現在給 AI 的授權是直接開放的,沒有同等的治理設計護著它。
Aiworks 認為,企業導入 AI Agent 的過程,需要把以下問題納入設計:
- 這個 AI 的行動能力邊界在哪裡?邊界由誰設定、由誰審查?
- 如果它做了一件不應該做的事,稽核路徑是什麼、責任怎麼歸屬?
Prompt injection 的問題不會隨著模型變聰明而消失,它會隨著模型能做的事情變多而改變形態。在 AI 代替人執行更多真實世界動作的趨勢下,攻擊技術和防禦方法都還在持續演變。
企業真正要問的問題,不是「我們的 AI 工具安不安全」,而是「我們授權給 AI 的方式,有沒有假設它可能被操縱」。Prompt injection 的風險,不過是在提醒我們:外部環境是敵意的,而你的 AI 還在假設它是中立的。
📩 想為你的組織打造 AI 協作能力?
Aiworks 提供企業內訓、客製化培訓與實作工作坊,協助各產業團隊規劃生成式 AI 的導入與應用策略。
▼ 聯絡我們|規劃你的 AI 實戰課程,讓轉型真正落地 ▼
(若表單未正常顯示,請點擊此連結進入表單填寫頁面)
推薦延伸閱讀
▶︎ 當 AI Agent 開始替你談判:從 Anthropic 實驗看企業導入前必須釐清的三個關鍵問題
▶︎ 2026 AI 指數報告關鍵洞察:Agentic AI 已成新基準,企業三道缺口同步擴大
▶︎ 什麼是 Harness?從 Anthropic 事後檢討報告看 AI Agent 背後的企業駕馭責任
▶︎ 2026 Anthropic 經濟指數報告解析:AI 如何重塑知識工作與企業專業價值
▶︎ 什麼是 AI Agent?一窺 2025 最重要企業 AI 應用趨勢