與 AI 或 Agent 深度協作的工作者常會遇到一個困擾:對話中得不斷向它說明你的工作習慣、個人重要資訊,但偶然提及的某件小事,卻被 AI 深深記住、當成關鍵偏好。而在多工具並用時,每次切換到新的 AI,又得從零開始建立工作脈絡,轉換成本讓不少人打退堂鼓。
OpenAI 在 2026 年 6 月 5 日宣布對 ChatGPT 的記憶機制進行了一次架構級的更新: 讓 ChatGPT 開始「做夢」! 而這個機制處理的,正是「過時、不正確、難以規模化」3 個 AI 記憶的老問題。
本篇 Aiworks 將從 OpenAI 本次的記憶機制更新出發,帶你理解 AI 記憶如何運作、各家業者的設計差異,以及當記憶從「綁定」變成「可攜」之後,企業使用者在 AI 協作中真正該守住的脈絡是什麼。
認識 AI 記憶機制:兩種主流運作路徑與共通設計原則
早期使用 AI 時,每開一個新對話,你都得重新介紹自己一次:我是誰、在哪間公司、做什麼工作、有哪些不能踩的雷點。面對一次性任務時尚可接受,但如果這是一個需要重複執行數十次、數百次的任務,每次重述脈絡的成本就會堆得很高。AI 的記憶機制就是為了解決這個困擾:讓 AI 在跨對話之間累積對你與任務的理解,讓協作得以延續。
AI 如何「記憶」,大致可以拆成兩種路徑:
- 使用者明說的偏好,例如 ChatGPT 儲存的記憶、個人資訊欄位、自訂指令等。這類是由你主動告知系統並儲存的記憶,特性是明確、可控,但需要你花心力維護。
- AI 從歷史對話自動萃取的脈絡,例如 ChatGPT 的聊天歷程紀錄。這類是由系統在背景中分析歷次對話、整理成的記憶狀態,特性是覆蓋面廣,但仰賴 AI 自行判斷哪些值得記住。
常見的 AI 工具大多有類似的記憶機制,可見各家服務商已把記憶視為個人化體驗的核心,同時強調它是需要慎重處理的隱私議題。像 ChatGPT、Claude、Gemini 都允許使用者檢視、編輯、刪除記憶,或提供「不留痕跡」的對話模式,讓敏感對話不會被寫入記憶系統。至今記憶機制已經從「實驗性附加功能」變成 AI 工具的標準配備。
2026 年 AI 記憶移轉成新標配:Claude、Gemini、Codex 同步開放可攜性
在記憶機制普及後,它便形成 AI 工具的隱形護城河。 使用越久、教得越多,使用者就會越覺得「AI 很懂我」而越難離開。 隨著各家 AI 工具的功能差距逐漸縮小,許多使用者選定某一家 AI 之後就停留下來,因為重新建立工作習慣與個人資訊的脈絡實在太麻煩,形成逐漸堆疊的轉換成本。
2026 年起,這條護城河開始被各家服務商打通:
- Anthropic 在 2026 年 3 月更新了 Claude 的記憶匯入功能,提供一段標準化的 prompt 讓使用者從其他 AI 匯出記憶清單,再貼進 Claude 的記憶設定,Claude 就會自動消化並寫入自己的記憶系統,整套流程一分鐘內可以完成。
- Google Gemini 在同月月底跟進,除了複製貼上式的記憶匯入,Gemini 還支援以壓縮檔上傳完整對話紀錄,讓使用者可以把另一家 AI 的對話歷史整批帶進來。
- OpenAI 則是在 2026 年 5 月針對 Codex 推出記憶遷移工具,可以從其他 AI agent 匯入自訂的偏好指令、檔案、環境設定、Skills、MCP 配置、最近 30 天的對話紀錄⋯⋯等。
各家 AI 服務商的行動都表現出「鼓勵使用者將記憶帶來自家產品」。 一方面,這反映各家對自家產品能力的信心;另一方面,這也反映市場壓力。當所有人都允許匯入,獨自綁住使用者反而會讓自己的工具看起來不夠開放。對使用者及採用的企業而言,轉換成本急遽下降,衡量 AI 導入或轉換的要點也大幅改變。
ChatGPT 記憶機制更新解析:合成原理與 3 個品質評估維度
回到開場提及的 ChatGPT 記憶機制更新,OpenAI 這次發布的核心,是一套以「做夢」(dreaming)為基礎重新打造的記憶架構。
類似於在人類的睡眠科學中,觀察到「夢境」反映出了睡眠中正在進行的記憶重新活化與整合,ChatGPT 的「做夢」就是在背景中跨越大量歷史對話、自動萃取脈絡,再把這些訊號整理合成(synthesize) ChatGPT 的記憶。
合成後的記憶將會集中在記憶摘要(memory summary)頁面。從這個頁面,你可以快速看到 ChatGPT 認得的關鍵資訊摘要、直接新增或修改個人資訊,或下指令告訴 ChatGPT「以後遇到某個話題時請主動提起/不要再提」。如果想針對某一塊內容深入了解 ChatGPT 究竟記得什麼,在對話中直接問它即可。這讓記憶從一條條孤立的字串,升級成可以瀏覽、編輯、下指令的整體狀態。
在「做夢」時,ChatGPT 如何決定「什麼樣的記憶才算品質良好」?OpenAI 也公布了 3 個評估維度:
- 是否有把有用的脈絡帶到下一次對話(Carry forward useful context):你告訴 ChatGPT 一次某件事,它就會在後續對話中記得這個資訊,不需要再從頭介紹或描述一次。例如當你向 ChatGPT 諮詢採購相機周邊設備的資訊時,如果過去曾在對話中提及你的相機型號,ChatGPT 就會依據對「相機型號」的記憶,向你推薦符合你相機的產品。
- 是否有遵守偏好與限制(Follow preferences and constraints):當你描述了某個偏好,ChatGPT 在後續行動上就應該與這個偏好保持一致。例如你曾表達你吃素,或偏好野生動物攝影,在你請 ChatGPT 規劃旅遊行程時,它就會依據你的偏好,推薦對應的景點。
- 是否有隨時間更新(Stay current over time):記憶應該把時間的推移納入考量。例如 ChatGPT 記下了「你正在規劃下週六的生日派對」,那 ChatGPT 必須知道這個「下週六」終究會到來,因為你不會永遠都在規劃「下週六的生日派對」。
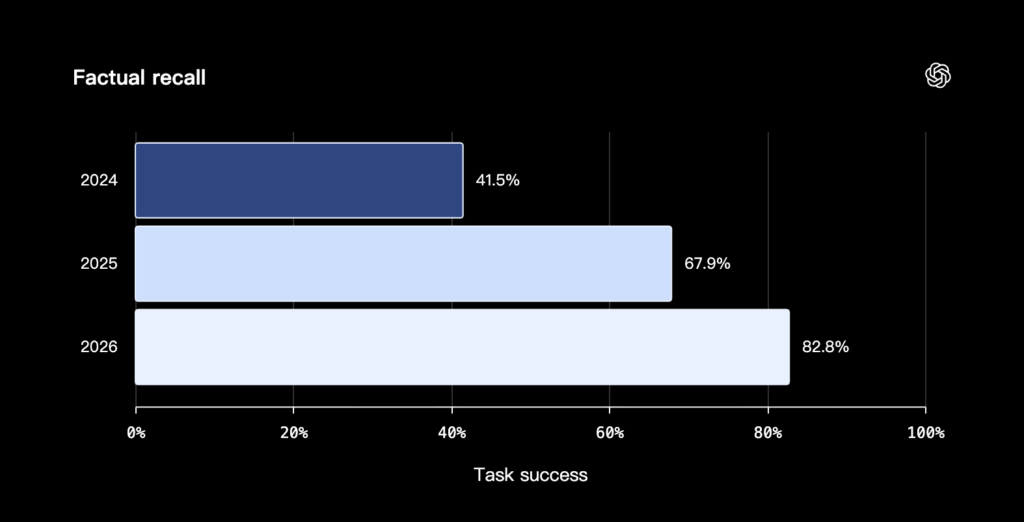
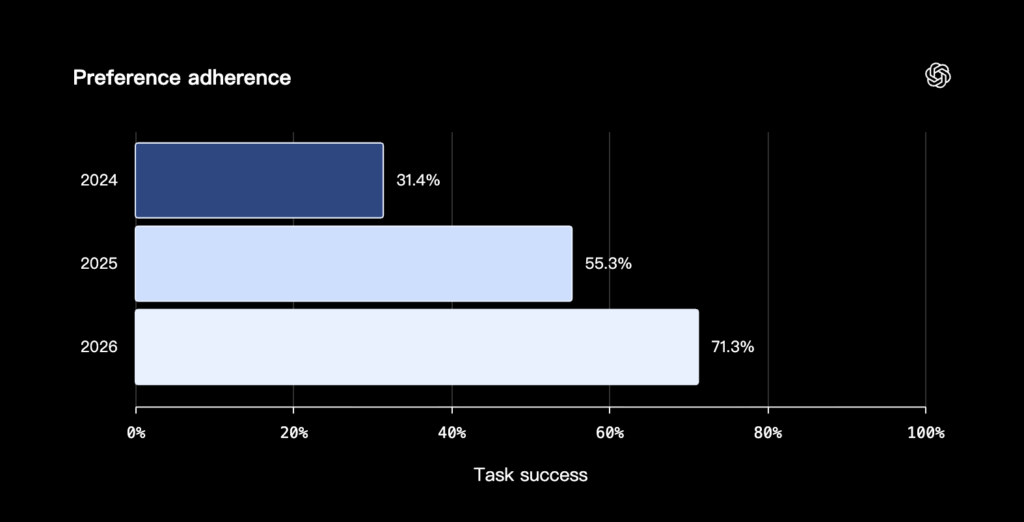
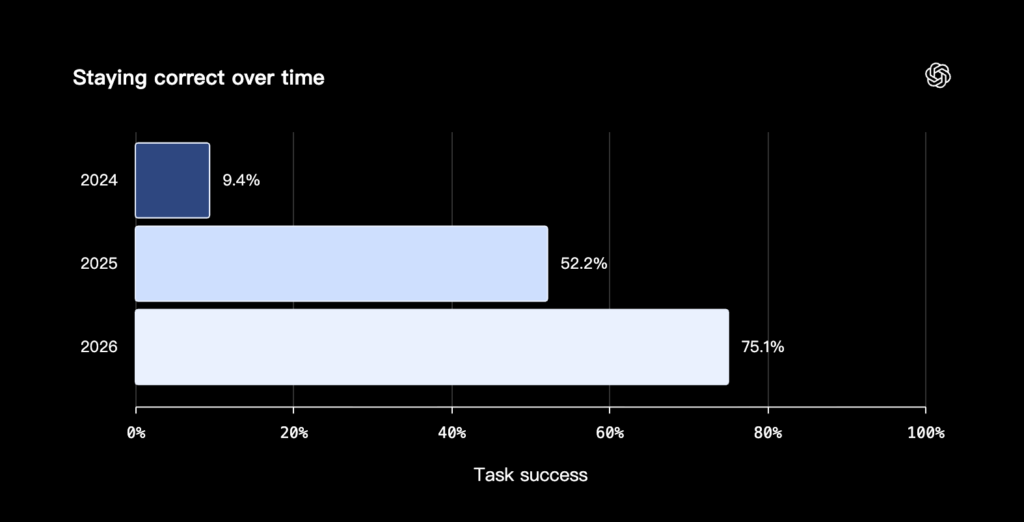
(source: Dreaming: Better memory for a more helpful ChatGPT, OpenAI)
在「做夢」的過程中,ChatGPT 把零散的對話片段整理成有用的脈絡並套用到下次對話,判斷哪些是穩定偏好、哪些是一次性需求,並隨時間推進,把過期的資訊改寫成更接近真實狀態的版本。
這樣的記憶脈絡相當龐大,但 OpenAI 卻表示,這次更新將原本記憶整合的運算成本降到原本的約 1/5。隨著運算成本下降,「做夢」的機制將可以在接下來幾週內陸續開放給免費用戶,付費方案使用者的記憶容量也會同步擴大。
Aiworks 觀點:AI 記憶加速協作,企業仍須親自守住關鍵脈絡
隨著記憶轉移成本大幅下降,各家服務商在記憶機制的競爭重點,轉向如何淬煉出最精準、簡約且品質良好的記憶,讓 AI 及 Agent 更「理解」使用者。
記憶也是 AI 上下文視窗(context window)的其中一環,記憶機制卻高度仰賴模型自行判斷哪些對話片段值得保留、哪些可以遺忘,由 AI 在定義「什麼是重要的使用脈絡」。但工作場景中真正關鍵的脈絡,例如重大決策的判斷依據、特殊規範的細節、不可動搖的合規限制,不應該賭 AI 會幫你記得。一旦這些脈絡被 AI 遺漏或誤判,後續輸出的所有判斷都會跟著偏移,而你甚至可能不會立刻察覺。
在任務或工作場景中,關鍵脈絡(context)應該由使用者主動明定,並寫進相對固定的位置,例如 Skill 或 AGENTS.md,且必須確保你可以審閱、可以編輯、AI 或 Agent 也可讀。把關鍵脈絡標示清楚,才不會被背景機制的判斷誤差影響,也更能確保工作流程可重複且可傳承。AI 記憶可以幫你加速協作,但協作品質的最後一道防線,仍取決於使用者與企業對自身脈絡的掌握。
想優先使用 ChatGPT 最新功能?
歡迎與 Aiworks 聯繫,了解 ChatGPT Business 及 ChatGPT Enterprise 的導入方案與服務內容 ▷ ChatGPT 導入 × Aiworks
📩 想為你的組織打造 AI 協作能力?
Aiworks 提供企業內訓、客製化培訓與實作工作坊,協助各產業團隊規劃生成式 AI 的導入與應用策略。
▼ 聯絡我們|規劃你的 AI 實戰課程,讓轉型真正落地 ▼
(若表單未正常顯示,請點擊此連結進入表單填寫頁面)
推薦延伸閱讀
▶︎ 不只屬於開發者!看 Codex 如何加速各職能知識工作流程
▶︎ 從 prompt 技巧到成果導向規格:AI Agent 時代與 GPT-5.5 高效協作的新標準
▶︎ 企業該如何使用 Codex?從工作場景到 Agent 時代的組織能力建立
▶︎ AI 同事正式上線!ChatGPT Workspace Agents 功能解析與企業導入建議
▶︎ ChatGPT Images 2.0 重點整理:推理能力、Codex 整合與中文渲染三大突破
參考來源
- Dreaming: Better memory for a more helpful ChatGPT|OpenAI
- Memory and new controls for ChatGPT|OpenAI
- Memory FAQ|OpenAI
- Migrate to Codex|OpenAI
- Bringing memory to Claude|Anthropic
- Switch to Claude without starting over|Anthropic
- Gemini gets personal, with tailored help from your Google apps|Google
- Make the switch: Bring your AI memories and chat history to Gemini|Google