Anthropic 於 5 月 6 日宣布將使用 SpaceX 的 Colossus 1 資料中心的完整運算容量,包含超過 300 MW 電力與超過 22 萬顆 NVIDIA GPU,預計一個月內取得使用權。就在同一則公告裡,Anthropic 同步宣布三項立即生效的用量改善:
- Claude Code 五小時用量限制翻倍
- 尖峰時段限制移除
- Claude Opus API 的用量限制大幅提升
新增運算容量,用量限制隨之鬆綁。這個因果放在一起看,說明了 AI 工具的日常使用體驗,如服務穩不穩定、用量夠不夠用、哪個方案值得升級⋯⋯等,背後有一條更長的供應鏈在決定它:資料中心、晶片、電力與雲端架構,以及 AI 服務商如何把這些資源整合成可交付的服務能力。
本篇 Aiworks 將從 Anthropic、OpenAI 與 Google 的運算資源佈局出發,說明 AI 服務商的基礎設施策略如何影響服務穩定性、用量限制、方案設計與企業採用判斷。
本文重點速覽
- 2026 年,AI 競爭已超越單純的模型能力比拚,進入一場以運算資源與基礎設施為核心的長期戰役。AI 產業當前最核心的瓶頸已是服務成本、運算資源、資本配置,以及雲端基礎設施的控制權。對使用者而言,用量限制、服務穩定性、方案分層、尖峰時段管制與計費模式,都是這場運算競賽在產品層面的外在症狀。
- OpenAI 透過 Stargate、多雲合作、大規模網路基礎設施建設,試圖把爆炸性的需求轉化為更穩定的使用者體驗。
- Anthropic 官方承認 Claude 的可靠性與使用限制在需求成長的壓力下受到影響,並正透過 AWS、Google 與 SpaceX 等合作夥伴補足中長期運算供給。
- Google 透過 TPU、AI Hypercomputer、Google Cloud 與 Gemini 整合,同時扮演模型競爭者與主要 AI 基礎設施供應者兩個角色。
從邊際成本到產業競爭:運算資源為何決定 AI 用量限制?
用量限制背後牽涉的,是 AI 服務商如何管理高成本的運算資源。
AI 服務和傳統網路服務有一個根本差異:使用強度直接影響邊際成本。你的請求越複雜、越耗算力,服務商每多服務你一次的成本就越高。進行一次一般對話、分析一份長篇合約、執行複雜的程式碼調試、跑完一段多步驟的 Agent 工作流程,背後消耗的運算資源可能相差幾十倍。使用者數量及使用強度快速成長,帶來的是更難以線性預測的資源消耗。
且在 Agent 時代,AI 已從個人工具逐漸轉為工作流程基礎設施。個人使用者對於延遲的寬容度較高,但被嵌入企業自動化流程或多步驟 Agentic AI 的任務,通常帶有時序依賴,前一個環節的降速會傳遞到後續步驟,影響整段工作流程的完成品質。與此同時,多個團隊同步發出高強度請求,讓後端資源壓力以快過使用者數量成長的速度積累。
放大到整個產業來看,這個壓力的規模更為清楚。根據史丹佛大學 2026 年度 AI 指數報告,全球 AI 運算容量自 2022 年起每年成長 3.3 倍,到 2025 年底達到約 1,710 萬個 H100 equivalent(以 H100 GPU 為基準的等效運算單位);AI 資料中心的總電力容量達到 29.6 GW,相當於紐約州的尖峰電力需求。
用量限制、尖峰管制與不同方案的額度差異,都是 AI 服務商在分配運算資源的工具,若在容量上受限,使用者就會最先感受到。因此誰能確保大規模穩定的運算供給,誰的服務就能繼續擴展用量、推進功能邊界。
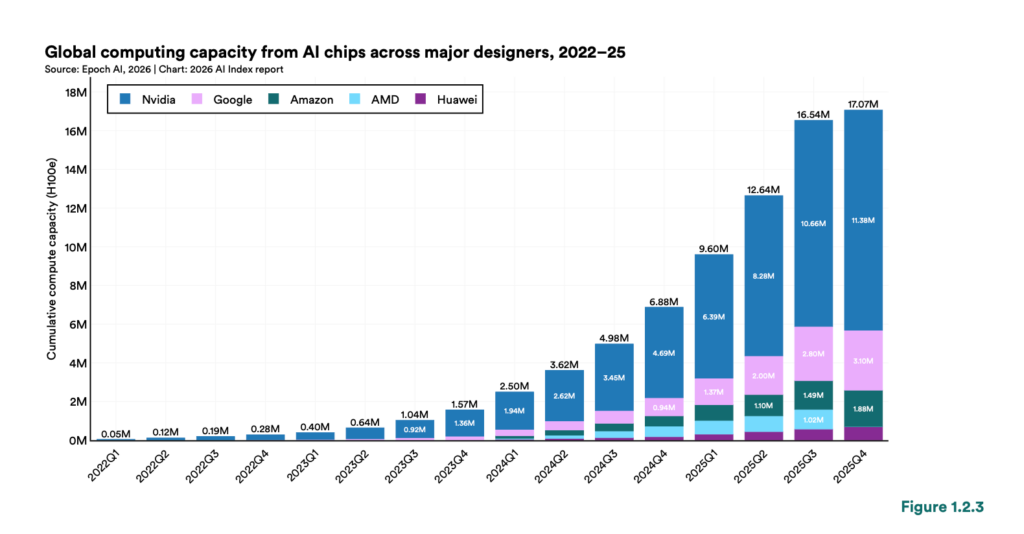
(source: Epoch AI, 2026|Chart: figure 1.2.3, 2026 AI Index report)
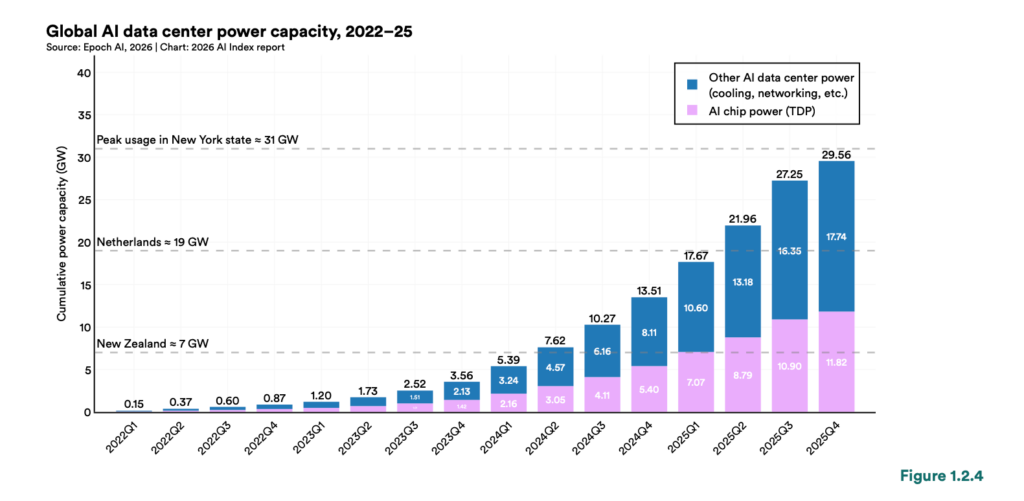
(source: Epoch AI, 2026|Chart: figure 1.2.4, 2026 AI Index report)
Anthropic:從用量限制爭議,到多供應商補容量
2026 年 3 月,Claude Code 使用者集中反映用量限制變得更難預測。部分 Pro、Max 使用者回報,原本應該支撐數小時的額度,在相同工作負載下更快耗盡,也有使用者懷疑 Anthropic 是否調整了計量方式,以致於更容易提前碰到限制。這波反應讓 Anthropic 面臨的問題變得很具體:Claude 的需求成長速度,已經快到需要調整使用者可用量與尖峰時段規則。
因此 Anthropic 除了與 SpaceX 合作,解決短期容量壓力,同時也持續透過多供應商合作,補上中長期的用量供應能力:
- AWS:主要訓練與雲端合作夥伴,包含 Project Rainier、Trainium2、Trainium3,並承諾最高 5 GW 容量。
- Google 與 Broadcom:提供下一代 TPU 容量,預計自 2027 年起陸續上線,用於支援 frontier Claude models。
- Microsoft 與 NVIDIA:讓 Claude 進入 Azure 與 Microsoft Foundry,並取得 300 億美元 Azure 容量承諾。
- Fluidstack:協助 Anthropic 建設專用資料中心,強化自有基礎設施掌控。
Anthropic 的策略可以總結為:先透過 SpaceX 運算資源,回應短期容量壓力,再透過 AWS、Google、Broadcom、Microsoft、NVIDIA、Fluidstack 等多供應商合作,降低單一供應商依賴,追上 Claude 快速成長帶來的運算資源缺口。
OpenAI:從 Sora 停止服務,到 Stargate 基礎設施整合
OpenAI 在 2026 年 3 月 25 日宣布 Sora 網頁版和 App 於 2026 年 4 月 26 日停止服務。從影片生成等高成本 AI 功能的發展策略,可以看出 OpenAI 正在調整高需求功能的產品配置、資源分配、使用方式與計費模式。
然而 OpenAI 的競爭重心不只停留於模型與軟體,而是往更上游的 AI 基礎設施控制權移動。
Stargate 是 OpenAI 自 2025 年啟動,為了取得長期 AI 運算資源而推動的美國大型基礎設施計畫。在 2026 年 4 月的官方說明中也提到,Stargate 不是單純的資料中心建設案,而是一個以運算資源為核心的 AI 基礎設施生態系,這種規模的基礎設施不可能由單一公司獨自完成,必須協調地方社群、公用事業、能源供應商、晶片商、雲端供應商、資料中心業者、建設公司、投資人、技術工人與公部門。不只是取得更多晶片,而是把電力、土地、資料中心、雲端、晶片、資金與建設能力整合成可持續擴張的 AI 供給系統。
OpenAI 表示,AI 使用需求正在快速成長,而滿足這個需求的方式,是更快建設更多運算資源,以訓練更好的模型、更可靠地提供服務、改善效能、長期降低成本,並把更強大的工具帶給更多使用者與企業。
Google:從自有 TPU 到 Gemini Enterprise,把基礎設施變成平台能力
Google 在 AI 競爭格局裡同時具備兩個身份:模型層上的競爭者,基礎設施層上的供應者。和 OpenAI、Anthropic 相比,Google 的特殊性在於它長期擁有自家資料中心、Google Cloud、TPU 晶片、Gemini 模型與企業應用入口,這讓 Google 可以把 AI 供應鏈從底層算力,一路整合到企業實際使用 AI 的平台。如 2026 Google Cloud Next 大會宣布的一系列創新技術,更印證了這一點。
例如 AI Hypercomputer 可以理解為這套平台的底層架構:它把 TPU、GPU、資料中心網路、運算叢集與軟體管理工具整合在一起,支撐大型模型訓練、低成本推論與企業 AI 應用,讓 Google 自家的 Gemini 服務和 Google Cloud 客戶都能建立在同一套基礎設施上。
在這套架構中,TPU 是最關鍵的底層能力。Google 在 2026 Cloud Next 大會推出第八代 TPU,分成兩種用途:
- TPU 8t:負責大型模型訓練,目標是把前沿模型的開發時間從數月縮短到數週。
- TPU 8i:負責推論、reasoning 與 Agentic AI 工作負載,目標是讓使用者在即時互動、多步驟任務與高併發情境下更快得到回應,Google 官方稱每元推論效能比上一代提升 80%。
Google 的策略重點,在於它把自有基礎設施、Gemini 模型與企業平台放在同一條供應鏈上。底層的 TPU 和 AI Hypercomputer 支撐模型訓練與推論,上層如 Gemini Enterprise Agent Platform 等平台則把這些能力轉成企業可以使用、治理與擴張的 AI agent 系統。
穩定性成為新分水嶺:運算資源與基礎設施佈局如何影響企業長期採用?
過去幾年,企業評估 AI 工具時,看的是模型排行榜、功能清單,以及哪家服務商的 API 串接更廣。在各家模型能力尚有明顯差距時,聰不聰明、能做的任務多不多,確實是關鍵判斷依據。
但如同史丹佛大學 2026 年度 AI 指數報告在總論中直接點出:
“At the technical frontier, leading models are now nearly indistinguishable from one another.”
「在技術前沿,各家頂尖模型之間的差距已幾乎難以分辨。」
—— Yolanda Gil and Raymond Perrault, Co-chairs, AI Index Report
各家主要模型的能力已跨過多數企業場景的可行門檻,競爭的分水嶺正在移動,穩定性成為下一道關卡。
在試點階段,這些差異通常不會馬上浮現。一旦 AI 真正進入客服、法務、產品、財務、工程或管理流程,用量限制的影響就從個人使用體驗擴大到工作流程的連續性,服務穩定性就會從使用體驗問題變成流程設計問題。
AI 競爭的主戰場從模型移向基礎設施控制權,這影響了一個更上游的問題:哪些 AI 能力能趨於成熟、哪些技術路線有資源繼續推進。服務商的基礎設施佈局,是觀察整個 AI 能力走向的上游線索,也是評估長期採用風險時,需要被納入的維度。
想像一下,如果 AI 工具在尖峰時段降速、限量或出現錯誤,工作流程因此停滯或終止,你的組織該如何應對?
📩 想為你的組織打造 AI 協作能力?
Aiworks 提供企業內訓、客製化培訓與實作工作坊,協助各產業團隊規劃生成式 AI 的導入與應用策略。
▼ 聯絡我們|規劃你的 AI 實戰課程,讓轉型真正落地 ▼
(若表單未正常顯示,請點擊此連結進入表單填寫頁面)
推薦延伸閱讀
▶︎ AI 在說真話嗎?揭示 AI 討好行為如何影響人的決策判斷
▶︎ Tokenmaxxing:當燒 token 變成競賽,企業衡量的是 AI 生產力還是幻覺?
▶︎ Agent 時代的新型資安威脅:Prompt Injection 如何讓 AI 工具變成攻擊者的入口
▶︎ 當 AI Agent 開始替你談判:從 Anthropic 實驗看企業導入前必須釐清的三個關鍵問題
▶︎ 什麼是 Harness?從 Anthropic 事後檢討報告看 AI Agent 背後的企業駕馭責任
參考來源
- Higher usage limits for Claude and a compute deal with SpaceX|Anthropic
- The 2026 AI Index Report|Stanford HAI
- Anthropic and Amazon expand collaboration for up to 5 gigawatts of new compute|Anthropic
- Anthropic expands partnership with Google and Broadcom for multiple gigawatts of next-generation compute|Anthropic
- Microsoft, NVIDIA and Anthropic announce strategic partnerships – The Official Microsoft Blog|Microsoft
- Anthropic invests $50 billion in American AI infrastructure|Microsoft
- Announcing The Stargate Project|OpenAI
- Building the compute infrastructure for the Intelligence Age|OpenAI
- What to know about the Sora discontinuation|OpenAI Help Center
- AI infrastructure at Next ‘26|Google Cloud Blog
- AI Infrastructure|Google Cloud
- Introducing Gemini Enterprise Agent Platform|Google Cloud Blog