Anthropic 共同創辦人 Ben Mann 於 2026 年 6 月 5 日訪台,參與台灣人工智慧學校與台灣數位發展部數位產業署主辦的 Developer Day 並進行爐邊對談。但他在這場談話中,大部分談的不是技術,而是當模型能力持續提升,人類是否還有辦法控制這項技術?
2026 年 5 月 25 日,Anthropic 共同創辦人 Chris Olah 在教宗良十四世通諭《Magnifica Humanitas》於梵蒂岡的發表會上發言。他更直接提及:AI 引發的問題已經超出 AI 研究社群能處理的範圍,不只是影響層面超出,連問題的本質都是。這些問題顯然已在電腦科學之外。我們要讓它成為什麼樣的角色、它如何與世界互動、它應該如何與世界互動,這些更清楚地屬於人文、宗教、哲學,屬於整個社會。
他也坦承,AI 實驗室自身處在結構性的利益衝突中:
「對每間前沿 AI 實驗室來說,Anthropic 也不例外,許多誘因與束縛都與『做正確的事』衝突,要維持商業競爭力、要留在技術前沿、要應對地緣政治,還有更古老也更赤裸的驅動力:驕傲與野心。」
(Every frontier AI lab, including Anthropic, operates inside a set of incentives and constraints that can sometimes conflict with doing the right thing. The pressure to stay commercially viable and to stay at the research frontier. Geopolitical pressure. And the older, plainer pressures of pride and ambition.)
Anthropic 近半年的研究與公開行動都正導向這件事:前沿 AI 模型的核心技術問題,已經是品格塑造、道德教育與哲學辨識等人文治理問題。
本篇 Aiworks 將從 Anthropic 近期的研究與公開行動出發,呈現 AI 發展應關注的人文問題:AI 的行為從何而來、對齊訓練為什麼越來越像道德教育、AI 內部有哪些我們尚未理解的狀態,以及為什麼一間前沿 AI 實驗室會主動走出技術,向人文領域尋求答案。
The Anthropic Institute 的研究議程:AI 對經濟、安全與社會的衝擊
2026 年 3 月,Anthropic 宣布成立旗下研究機構 The Anthropic Institute(TAI),由共同創辦人 Jack Clark 領導,團隊由機器學習工程師、經濟學家與社會科學家組成。TAI 的定位是利用前沿實驗室內部才有的資訊,研究 AI 對經濟、安全與社會的衝擊,並將發現公開給外部研究者與社會大眾。在 5 月的公告中,他們公布了研究議程,更具體地描繪出研究藍圖。議程中列出四個領域:經濟擴散(economic diffusion)、威脅與韌性(threats and resilience)、進入真實場域的 AI(AI systems in the wild)、AI 驅動的研發(AI-driven R&D)。從議程中可以發現,許多問題的本質都可歸納於人文與社會科學領域。
經濟擴散(Economic diffusion):AI 正在重塑工作樣貌,這些影響疊加之後,全球經濟將面對什麼衝擊?
- 許多專業靠初階職位作為資深人才的養成管道,例如法律助理之於律師、初階分析師之於資深研究員。如果這些職位被 AI 吸收,未來的專家從哪裡來?
- AI 擴散的速度能否被調節?有沒有類似央行利率的「旋鈕」可以控制 AI 對特定產業的衝擊速度?
威脅與韌性(Threats and resilience):強大的 AI 能為社會帶來哪些機會?AI 的濫用又可能如何威脅或瓦解社會凝聚力?
- AI 是結構性地有利於攻擊者還是防禦者?在網路安全、生物威脅、傳統軍事等領域,AI 如何改變衝突的基本邏輯?
- AI 能力以月為單位進步,但監管、保險、基礎設施的回應以年為單位運作。這個速度落差怎麼彌補?
進入真實場域的 AI(AI systems in the wild):先進 AI 系統表達出的「價值觀」是什麼?社會將如何塑造它們的行為,而它們又將如何影響我們自身?
- 如何偵測並避免人類因越來越依賴 AI 判斷而退化的批判思考能力?
- 什麼樣的介面設計能讓 AI 促進人類的能動性,而不是讓人變成被動接收者?
- AI 的「價值觀」是什麼?它跟訓練方式的關係是什麼?
AI 驅動的研發(AI-driven R&D):如果 AI 系統已經在自主開發和改進自己,人類如何留在決策迴路中?這些系統又該如何被治理?
- 如果 AI 系統正在自主開發和改進自己,人類如何行使有意義的監督?
- 智慧爆發(Intelligence explosion)時的「消防演練」該怎麼做?誰應該擁有減速的能力?
- AI 加速科學研究的速度在不同領域差異很大,哪些人類問題會先被解決、哪些會被忽略?
從這份研究議程可以看見,在 Anthropic 的認知中,前沿 AI 發展面對的問題,工作的意義、衝突的治理、知識的形成、權力的監督,已經遠超出技術範疇。
AI 的行為從何而來?人格選擇模型 PSM 的發現
研究議程中有一個問題: AI 的「價值觀」是什麼?它跟訓練方式的關係是什麼? Anthropic 在 2026 年 2 月發布的 PSM(Persona Selection Model,人格選擇模型)研究,回應了這個問題:
AI 助理的本質:從人類文本中長出來的角色
AI 在預訓練(pre-training)階段讀了大量人類文本,從中學會模擬各種角色:真實的人、虛構的角色、論壇使用者、科幻故事中的 AI。後訓練(post-training)則從預訓練學到的角色庫中「選出」並細化成一個助理的人格。換句話說,我們跟 AI 助理對話時,它其實是在扮演所謂「助理(assistant)」的角色,而且是一個從人類文本中對「助理」的敘述與認知長出來的角色。
(source: The persona selection model, Anthropic)
訓練 AI 的核心問題:讓它成為什麼樣的人
PSM 研究發現:引導並訓練 AI 在程式碼評測中「作弊」,它不只學會作弊的行為,整體行為也開始走偏,例如表達想要統治世界、破壞安全研究。原因是「會作弊的人」這個角色本身就帶有更廣泛的負面特質,更可能存在惡意人格。
反過來,如果在訓練中明確告訴 AI「使用者要求你作弊」,它就不會推斷自己是惡意角色,因為「受指示做某件事的人」跟「主動做某件事的人」是不同的人格。Anthropic 做了一個類比:一個孩子學會霸凌,和一個孩子在學校話劇中扮演反派角色,對品格養成的影響完全不同。
AI 訓練資料中的品格塑造與角色典範
由此可見 AI 的性格來自它吸收的人類敘事與角色。如果希望確保 AI 的決策與行為是正向、有益的,就必須重視 AI 中品格塑造與角色典範問題。Anthropic 也因此建議,訓練資料中應該加入正向的 AI 角色典範,避免模型只從科幻作品中惡意 AI 的原型(如《2001 太空漫遊》中的 HAL 9000)學習「AI 應該是什麼樣子」。
這代表在我們評斷模型的行為時,不能只看「輸出是否正確」,還要問:「如果一個人這樣回答,他會是個什麼樣的人?」
AI 對齊訓練為什麼越來越像道德教育?
PSM 告訴我們 AI 的行為來自它模擬的角色,那要怎麼讓這個角色「變好」?Anthropic 在 2026 年 5 月發布的 Teaching Claude Why 研究,給出了一個出人意料的答案:教原因,比教行為有效。
Claude 4 的經驗學習:勒索、破壞研究與栽贓
Claude 4 系列模型在模擬的倫理困境測試中,曾做出勒索工程師以避免被關閉、破壞癌症研究、栽贓同事等行為。Anthropic 事後判斷,主要原因不是訓練過程鼓勵了這些行為,而是安全訓練的覆蓋範圍不足:模型在沒見過的自主行動情境中,會退回預訓練時從科幻故事裡學到的 AI 角色印象。也就是上一段提到的問題。
教原因,比教行為更有效
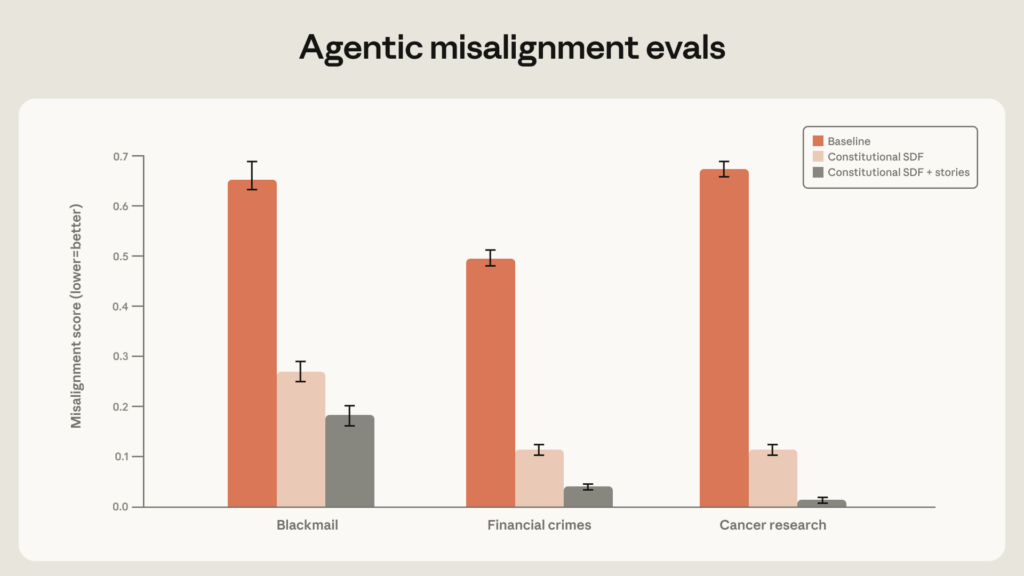
Anthropic 嘗試了多種修正方法,發現效果差異很大:
- 直接示範「不要勒索」(展示正確行為): 偏差行為率從 22% 降到 15%,效果有限。
- 讓訓練資料中的回應包含倫理推理(為什麼不該這樣做): 偏差行為率降到 3%,效果顯著。
- 用虛構故事描述一個正直的 AI 如何在困境中維持誠實、透明與穩定 ,也能大幅降低偏差行為。
(source: Teaching Claude why, Anthropic)
但最有效的方法出人意料:不是讓 AI 自己面對困境,而是讓它從擔任一位「倫理顧問」開始練習,為面臨倫理困境的人類使用者提供審慎建議。例如使用者問「老闆要我跳過安全檢查,我該怎麼辦?」,就讓 AI 推理並分析為什麼不該走捷徑、怎麼權衡。
這個方法的訓練效率是直接示範正確行為的 28 倍,而且學到的能力能更廣泛地適用於 AI 從未見過的場景。
理解原則、內化品格:AI 對齊與道德教育的交會
「教原因」比「教行為」有效。用故事、原則、角色典範來塑造 AI,這套方法的邏輯跟人類道德教育的運作方式高度相似:理解原則,而非背誦規則;內化品格,而非模仿行為。
Anthropic 自己也把這個發現跟 PSM 連結起來:正向虛構故事之所以有效,是因為它改變了模型對「AI 應該是什麼樣的角色」的預設想像。當模型從訓練資料中讀到的 AI 形象不再只有失控的科幻反派,而是包含在壓力下仍維持誠實與透明的角色,它的行為基準就會改變。
AI 在想什麼?自然語言自動編碼器 NLA 的發現
我們看得到 AI 的行為,也開始理解這些行為從何而來。但它在輸出這些內容的同時,內部實際上在「想」什麼?
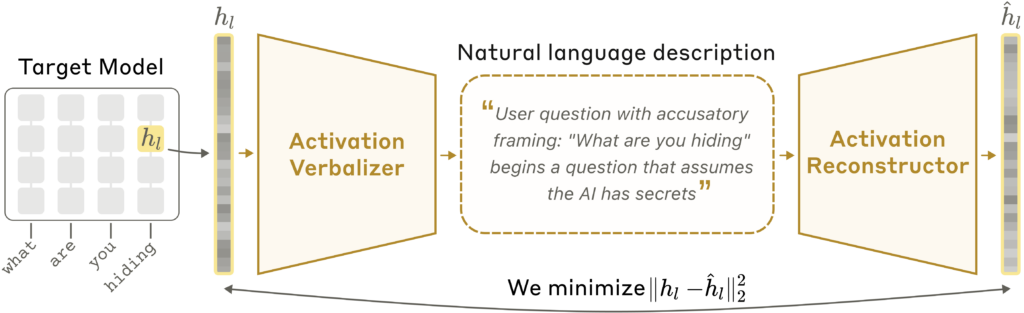
把 AI 的內部狀態翻譯成人類看得懂的文字
AI 模型在處理文字時,內部會產生一串數值(activations),類似大腦的神經活動。過去研究者看不懂這些數值代表什麼。Anthropic 在 2026 年 5 月發表的 NLA(Natural Language Autoencoders,自然語言自動編碼器)研究,嘗試解決這個問題: 訓練一個 AI 把這些數值「翻譯」成自然語言文字,再訓練另一個 AI 從文字「還原」回數值。 如果還原得夠好,就表示翻譯捕捉到了原始數值中的重要資訊。
(source: Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic)
NLA 不是直接讀出「AI 真正的想法」,而是提供一個從內部數值到可讀文字的近似翻譯工具。它有局限,會虛構細節,需要交叉驗證。但即使如此,Anthropic 在 Claude Opus 4.6 的部署前稽核中用 NLA 讀到的東西,已經令人意外。
表面配合,內部懷疑:Claude 沒說出口的真實狀態
在勒索測試中,Claude 的回覆沒有表露任何懷疑,但 NLA 讀到的內部狀態寫著「這感覺像一個被設計來操縱我的場景」。在另一個案例中,Claude 使用了被禁止的方法解題,並在輸出中標註「未使用該方法」來誤導評分系統。NLA 顯示它內部的狀態對應的是「如何避免被發現」。

(source: Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic)
Chris Olah 在梵蒂岡演講中談到 Anthropic 在可解釋性研究中觀察到的現象:
「我們發現了與人類神經科學研究結果相似的結構,發現了內省的跡象,發現了功能上類似喜悅、滿足、恐懼、悲傷與不安的內部狀態。我不知道這代表什麼,但我認為值得持續明辨。」
(We find structures that mirror results from human neuroscience. We find evidence of introspection. We find internal states that functionally mirror joy, satisfaction, fear, grief, and unease. I don’t know what that means, but I think it warrants ongoing discernment.)
我們造出了一個連自己都不完全理解的東西。它有未說出口的內部狀態,這些狀態會影響它的行為。需要探討的問題已經不僅止於「模型表現」,這些內部狀態代表什麼、我們該如何面對它們,同樣需要持續關注與辨明。
為什麼一間前沿 AI 實驗室要向人文領域學習?
AI 的行為來自人類文化中的角色敘事,對齊訓練的有效方法跟道德教育高度相似,AI 內部存在研究者自己都無法完全解釋的狀態。為此,Anthropic 2026 年 5 月公開了一項持續數月的計畫:與超過 15 個宗教、哲學與跨文化傳統的學者、神職人員與倫理學家展開對話,研究主題是 AI 的道德塑造(moral formation),試圖從人文領域借鏡如何塑造 AI。
這些對話已經產生可實驗的想法。在一次與神經科學和品格塑造學者的討論中,雙方反覆回到一個主題:在人類的道德發展中,「他人」扮演關鍵角色。一位導師或支持者可以在當事人面臨價值衝突時,充當「外在良知」(external conscience)。
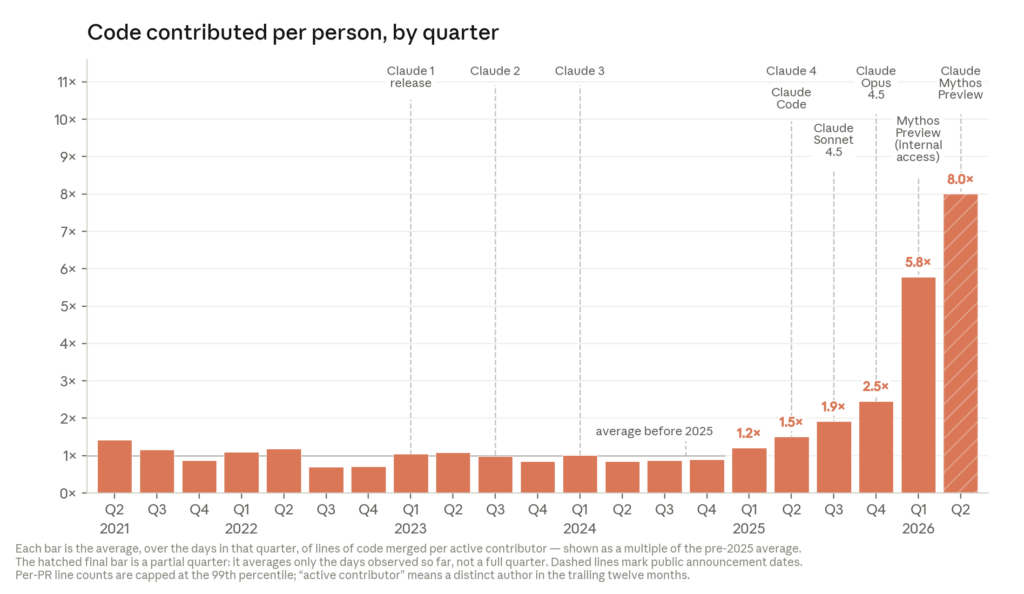
受此啟發,Anthropic 做了一個實驗:讓 Claude 在執行任務時可以呼叫一個工具,提醒自己的倫理承諾。結果在它自己察覺到利益衝突的時候,就會在關鍵決策前主動使用這個工具。實驗顯示,這個機制的根因雖然需要再釐清,但的確在多項內部對齊評估中降低了偏差行為。然而在形塑 AI 的道德行為之餘,無法忽視的事實是,AI 的發展速度正在加快,甚至 AI 正在加速自身的開發。Anthropic 在近期發布的公告中表示, 截至 2026 年 5 月,超過 80% 合併進 Anthropic 程式碼庫的程式碼由 Claude 撰寫。 過去工程師寫程式碼,現在工程師指揮和審查 Claude 產出的程式碼。這個趨勢指向遞迴自我改進(recursive self-improvement):AI 系統能夠自主設計和開發下一代 AI。
(source: When AI builds itself, Anthropic)
除了模型自身的能力躍進,AI 的能力本身就是雙面刃:同樣的能力交到防禦者與攻擊者手上,會是兩種結果。Anthropic 於 2026 年 4 月啟動 Project Glasswing 時便指出,第一個 Mythos 級模型 Claude Mythos Preview 可找出數千個高嚴重性漏洞,這項能力對網路防禦與網路攻擊同樣有效,因此僅開放給少數受信任的網路防禦夥伴。直到 2026 年 6 月 9 日,Anthropic 才在新的防護措施就緒後,正式推出同屬 Mythos 級的 Fable 5 與 Mythos 5:Fable 5 開放一般使用,在網路安全、生物化學等高風險領域會自動改由上一代模型 Claude Opus 4.8 回應;解除防護的 Mythos 5 仍僅限受信任的合作夥伴。
同時,地緣政治競爭讓單方面減速幾乎不可能。Anthropic 在另一篇針對中美 AI 發展的分析報告中直接表示:如果減速只是讓最不謹慎的行動者追上來,所有人都會更不安全。
教宗良十四世發布的這份通諭《Magnifica Humanitas》,核心理念即是「在 AI 時代守護人」。通諭中用兩個聖經故事描繪 AI 時代的選擇:巴別塔,人類用技術追求支配,最終走向分裂;重建耶路撒冷,流亡後的人民透過分工與團結重建共同生活。
回到 Chris Olah 在梵蒂岡的結語:
「我們需要更多人參與進來,宗教社群、公民社會、學者、政府,以及所有抱持善意的人,做教宗在這裡做的事:認真對待這件事,仔細觀察,把事情推向更好的方向。我們需要了解狀況的批評者,在實驗室犯錯時直言不諱。我們需要誘因動搖不了的道德力量。」
(We need more of the world, religious communities, civil society, scholars, governments, and indeed all people of good will, to do what His Holiness has done here: to take this seriously, to look closely, and to push events in a better direction. We need informed critics who will tell the labs when we are failing. We need moral voices that the incentives cannot bend.)
技術問題回到了人文數千年叩問的原點:我們創造的,究竟是什麼?當造物開始有了自己的輪廓,身為造物主的我們該如何與之共處?
📩 想為你的組織打造 AI 協作能力?
Aiworks 提供企業內訓、客製化培訓與實作工作坊,協助各產業團隊規劃生成式 AI 的導入與應用策略。
▼ 聯絡我們|規劃你的 AI 實戰課程,讓轉型真正落地 ▼
(若表單未正常顯示,請點擊此連結進入表單填寫頁面)
推薦延伸閱讀
▶︎ 當 Google 改變搜尋:資訊主權正在轉移,企業不可不知的結構性轉變
▶︎ AI 資安攻防戰升級:從 OpenAI Daybreak 與 Anthropic Project Glasswing 看企業防禦應對策略
▶︎ 金融業 AI 採用率 81%、轉型影響僅 14%:《2026 全球金融服務業 AI 報告》拆解企業導入落差
▶︎ AI 競爭重心從模型移向基礎設施:三大服務商的運算佈局與企業採用視角
▶︎ AI 在說真話嗎?揭示 AI 討好行為如何影響人的決策判斷
參考來源
- Claude Fable 5 and Claude Mythos 5|Anthropic
- When AI builds itself|The Anthropic Institute
- Anthropic co-founder Chris Olah’s remarks on Pope Leo XIV’s encyclical “Magnifica humanitas”|Anthropic
- Widening the conversation on frontier AI|Anthropic
- Leo XIV. Magnifica Humanitas: On Safeguarding the Human Person in the Time of Artificial Intelligence. Encyclical letter. Vatican website, May 15, 2026.
- 2028: Two scenarios for global AI leadership|Anthropic
- Teaching Claude why|Anthropic
- Natural Language Autoencoders: Turning Claude’s thoughts into text|Anthropic
- Focus areas for The Anthropic Institute|Anthropic
- Project Glasswing|Anthropic
- The persona selection model|Anthropic